*"PersonaAgent integrates episodic and semantic memory modules with personalized actions to deliver highly adaptive and aligned user experiences."*
*"Our test-time user preference alignment strategy optimizes the persona prompt by simulating recent interactions and minimizing textual loss between simulated and ground-truth responses."*
1. 개요
- 최근 LLM 기반 에이전트들이 다양한 업무에서 뛰어난 성능을 보이고 있으나, 사용자별 다양성 을 반영하는 데 한계가 있음. 기존 에이전트들은 대부분 하나의 시스템/도구 구성과 일반화된 prompting 방식(one-size-fits-all)에 기반하여, 개별 사용자 특성에 실시간(real-time)으로 적응하기 어렵다는 지적.
- 본 논문에서는 이러한 한계를 극복하기 위해 PersonaAgent 라는 프레임워크를 제안함. 이 프레임워크는 사용자별 페르소나(persona), 메모리(memory), 행동(action) 모듈을 통합해서, 사용자 특성/기호(preferences)를 테스트 시점에 정렬(test time user-preference alignment)가능하게 만드는 구조임.
2. 핵심 구성 요소
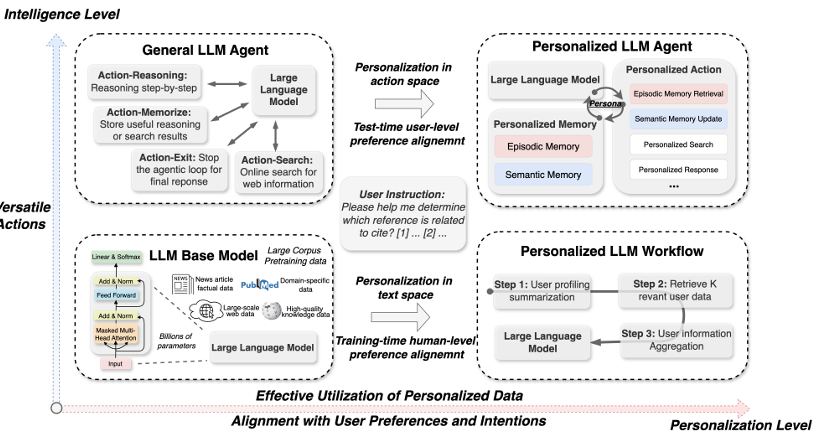
2.1 Persona, Memory, Action 모듈
- Persona: 각 사용자마다 고유한 시스템 프롬프트(system prompt)로 정의됨. 이 프롬프트는 사용자와의 상호작용 내역(personalized memory)을 기반으로 업데이트됨.
- Memory 모듈
- Episodic Memory: 과거 상호작용 쿼리, 응답, 메타데이터(시간, 세션 맥락 등)를 시간 순으로 저장. 사용자-질문과 유사한 과거 이벤트를 검색(retrieval)하여 현재 문맥(context)에 반영함.
- Semantic Memory: 반복적인 상호작용으로부터 안정적이고 지속적인 사용자 특성(preferences, 장기 목표 등)을 요약(sum-marization)하여 보다 추상적인 프로필(user profile)을 구성함.
2.2 Personalized Action 모듈
- 에이전트는 관찰(observation) 및 문맥(context)에 기반해 행동(action)을 선택함. 단순히 일반적 도구(general tool)만 사용하는 것이 아니라, 메모리 검색(memory retrieval)이나 유저 특화된 툴(personalized tools) 사용 등 사용자별 행동 공간(action space)을 조정함.
- 행동 선택(policy)은 페르소나(persona)에 의해 조율됨. 즉 사용자 특성과 메모리로부터 유도된 persona prompt가 행동(policy) 결정에 개입함.
2.3 Test-Time User-Preference Alignment 전략
- 테스크 수행 중 혹은 사용자와의 최근 상호작용(batch) 데이터를 이용해서 persona prompt를 최적화함. 구체적으로, 최근 (n)개의 상호작용을 시뮬레이션하여 에이전트 응답(agent responses)과 실제(ground truth) 사용자 응답 사이의 텍스트 손실(textual loss)을 최소화하는 방향으로 persona prompt를 업데이트함.
- 이 방법을 통해 “실시간(real-time)”으로 사용자 기호(preference)에 맞는 응답이 가능해짐. 또한 업데이트 수(iterations), 최근 상호작용 배치(batch) 크기, 검색된 메모리 수(retrieved memory)를 조절하여 성능과 효율성 간 균형을 맞춤.
3. 실험 및 결과
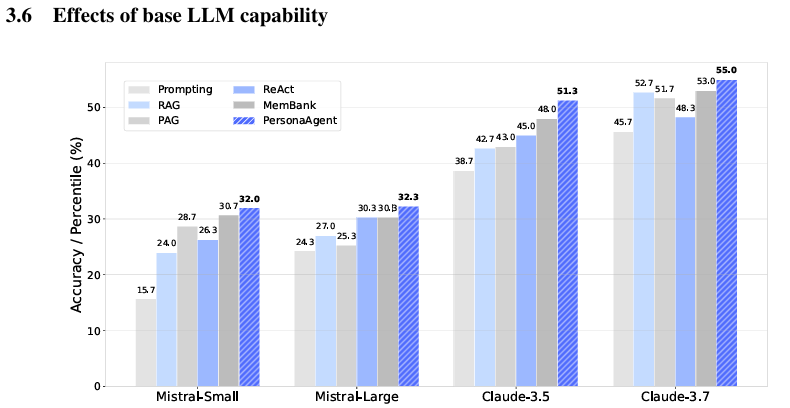
- 벤치마크: LaMP 데이터셋 LaMP-1 (Citation Identification), LaMP-2M (Movie Tagging), LaMP-2N (News Categorization), LaMP-3 (Product Rating) 의 4가지 개인정보(personalization) 의사결정(decision-making) 과제를 사용함.
- 비교 대상(baselines):
- 일반적인(non-personalized) 방법들 (기본 프롬프트(prompting), few-shot / in-context learning)
- 개인화 워크플로우(personalized workflow) 방법들: RAG, PAG 등.
- 일반 agent 기반 시스템: ReAct, MemBank 등.
- 주요 성능 결과:
- PersonaAgent는 네 과제 모두에서 baselines를 앞섬. 특히 사용자 특성 반영(user intent modeling)이나 사용자 기호에 맞는 태깅(movie tagging), 뉴스 분류(news categorization) 과제에서 정확도(accuracy), F1 점수 등이 유의하게 높았음.
- Product Rating 과제에서는 MAE, RMSE 등 오차(error) 지표에서도 PersonaAgent가 낮은 오차를 보이며 우수함.
- 구성 요소 기여 분석 (Ablation Study):
- Test-time alignment 없애면 성능 하락
- Persona prompt 제거 → memory-action 간 연결성(bridging) 손실
- Memory 모듈 혹은 Action 모듈 제거 → 전반적인 성능 저하
- 스케일링(scale) 실험:
- 백본(base LLM)의 크기/능력(model capacity) 변화에도 일반적으로 PersonaAgent 우위 유지됨 (작은 모델에서도 개선 효과 있음).
- 테스트 타임 정렬(batch size, number of memory retrieved, number of alignment iterations) 증가 → 성능 개선이 있으나 어느 정도 포화(saturation) 지점 있음.
4. 의미 및 기여
- 본 논문은 사용자 개인화를 단순한 프롬프트나 파인튜닝 방식이 아니라 에이전트(agent)의 행동(action) 공간, 메모리(memory), 그리고 persona prompt 간의 상호작용으로 통합시켜 설계한 점이 핵심임.
- 테스트 시점에서도 기호(preference)를 반영하는 업데이트(alignment)를 가능하게 함으로써 “실시간 사용자 적응(real-time user adaptation)” 가능성 보여줌.
- 다양한 도메인의 과제(task)에서 일반적인 방법 및 기존의 개인화 방법들을 비교하여 우수한 성능을 확보했다는 점에서 실제 응용 가능성이 높음.
- 또한 효율성과 확장성에 대한 논의도 포함됨: 작은 모델에서도 동작함, 메모리 검색이나 프롬프트 업데이트 반복 수를 조절하여 자원 제약 하에서도 적용 가능함.
5. 한계 및 앞으로의 과제
- 비언어적/멀티모달 신호의 부족
현재 사용자 선호를 텍스트 기반 상호작용과 명시적 responding으로만 모델링함. 감정, 음성, 시각 등의 암묵적 신호는 반영되지 않음. - 프라이버시 및 보안 이슈
개인화 메모리 및 테스트 타임에서의 사용자 데이터 활용이 많아지므로 개인정보보호, 데이터 유출, 사용자 동의 등의 고려가 요구됨. 논문에서도 이 부분을 한계로 언급함. - 비용 및 계산 자원의 관점
실시간 alignment, 메모리 검색, 프롬프트 최적화 등의 반복적 과정이 자주 일어날수록 비용이 증가함. 특히 사용자 수가 많거나 상호작용이 길어질 경우 오버헤드가 문제 될 수 있음. - 일반화의 경계
LaMP 벤치마크 과제들에서는 좋은 성능을 보였지만, 보다 복잡하거나, 사용자 특성이 매우 다양하거나, 도메인 특화된(task-specific) 환경에서는 얼마나 잘 작동할지 추가 검증 필요함. - 습득된 페르소나의 해석 가능성
페르소나가 latent representation으로 존재하고, 업데이트 되기는 하지만, 사용자에게 이 페르소나가 어떻게 형성되었는지, 왜 특정 응답 행동을 취하는지에 대한 해석이 쉽지 않음.
6. 결론
PersonaAgent는 LLM 에이전트 연구에서 사용자 개인화를 행동(action), 메모리(memory), 페르소나(persona prompt) 중심으로 통합하여, 테스트 타임에도 실시간으로 사용자 기호를 정렬(user preference alignment)하는 능력을 보여주었습니다.
실험적으로도 다양한 personalization task에서 우수한 성능을 입증했으며, 작거나 덜 강력한 LLM에서도 개선 효과가 나타나는 등 적용 범위가 넓습니다.
사용자 맞춤의 개인화가 최근 AI Agent들의 발전방향임에 따라 개인화 방법에 참고할 만한 연구였습니다.